
AI • Machine Learning • Tech
🤖 The No. 1 AI Page on Instagram
🌎 AI Education and Content
👇 Easy to read AI newsletter 📈
Recent Posts
Building an LLM app? Do it with Suna, your new AI employee. Developed by Kortix AI, Suna is a generalist AI agent that analyzes files, writes code, browses the web, and writes up documents, slideshows and spreadsheets in one click. Suna is 100% open source and can be hosted locally, offering full transparency, security and customization. Save time and get projects done with Suna.
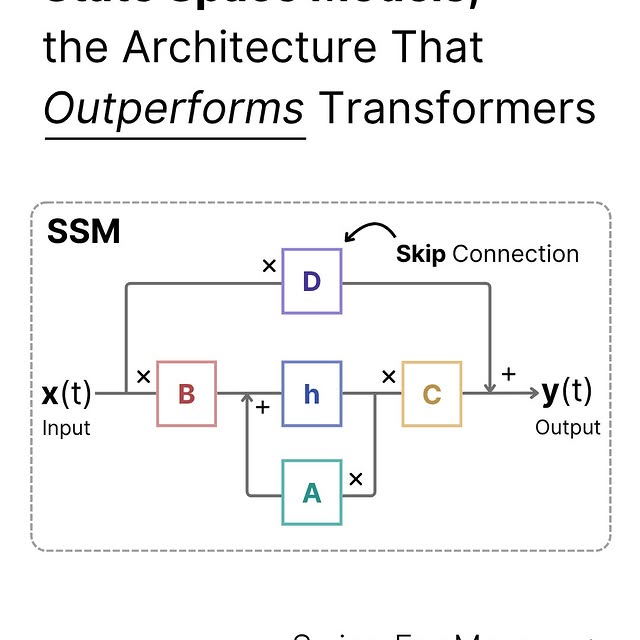
State space models (SSMs) are sequence models that represent data using hidden states over time. SSMs solve a fundamental problem with other text models like RNNs or transformers: RNNs can’t handle long-range dependencies, while transformers aren’t that efficient (they scale quadratically with input length). SSMs are the middle ground—being both efficient like RNNs and being able to handle long-range context like transformers by selectively compressing information into the hidden state. SSMs can be represented mathematically using two equations: the state equation and the output equation. The state equation is responsible for mapping the old state into a new one, and the output equation defines the mathematical relationship between the state, the input, and the output. There are many different types of SSMs. One such SSM is Mamba, or S6, and it has shown promising performance, matching and even sometimes exceeding performance in transformers of the same size. Mamba takes previous SSM innovations like HiPPO (high order polynomial projection operators) and introduces new algorithmic optimizations that help it better understand the actual content and meaning of input tokens, along with hardware-aware algorithms that speed up training and inference. Like this post? Accelerate your learning with our Weekly AI Newsletter; learn industry knowledge without the headache. It’s educational, easy to understand, mathematically explained, and completely free. #statespace #deeplearning #coding #mathematics #math #computerscience #science #education #computerengineering #statistics #datascience #mamba
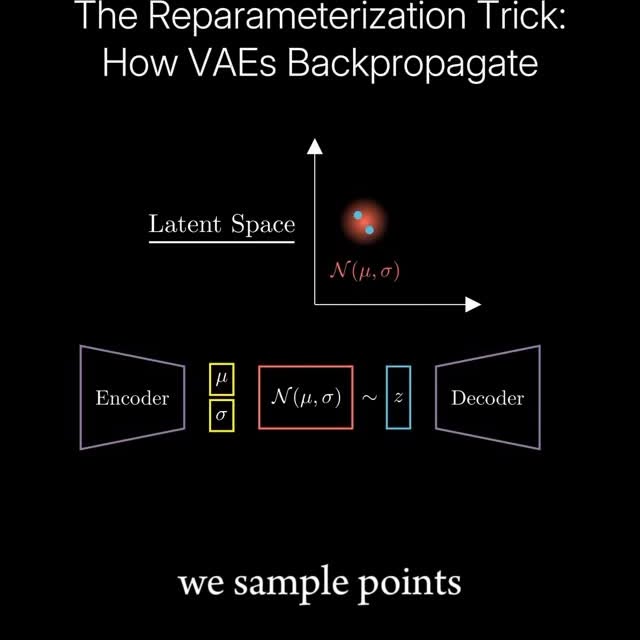
The reparameterization trick is a clever technique used in Variational Autoencoders (VAEs) to make the training process possible using standard gradient-based optimization. Normally, VAEs learn to generate data by first learning a distribution (like a Gaussian) from which to sample, but sampling from this distribution means we can’t backpropagate the loss to update the model (we can’t differentiate a sampling process!). The reparameterization trick solves this by expressing the random sampling as a deterministic function: instead of sampling directly from the learned distribution, we sample from a fixed distribution (like a standard normal) and transform it using the learned parameters (mean and standard deviation). This allows gradients to flow through the network and makes the whole system trainable end-to-end. Struggling with ML? Accelerate your ML learning with our Weekly AI Newsletter—educational, easy to understand, mathematically explained, and completely free (link in bio 🔗). C: Deepia Join our AI community for more posts like this @aibutsimple 🤖 #deeplearning #neuralnetworks #mathematics #math #physics #computerscience #coding #science #education #machinelearning #datascience
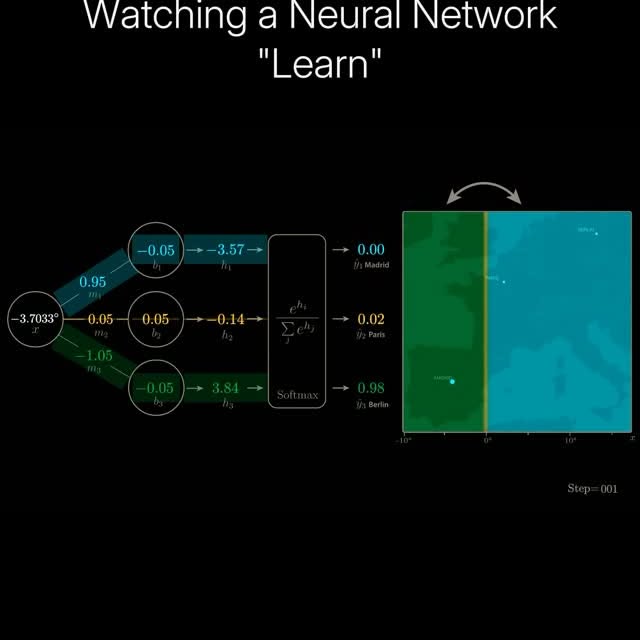
A neural network “learns” by adjusting its parameters (weights and biases) by increasing or decreasing them numerically so that the network can make increasingly more accurate predictions. The output is compared to the actual target values using a loss function, which quantifies the prediction error. To minimize the error, the network performs backpropagation, an algorithm that computes the gradient (set of all partial derivatives) of the loss with respect to each parameter using the calculus chain rule. The parameter values are changed through the backpropagated gradient, and depending on the error, will have a large shift or a smaller shift. For instance, if the model hugely misclassifies a “Paris” point as Berlin, the model, using the loss, will send a strong signal to the parameters affecting this classification to either increase or decrease the numerical values to make the model more likely to predict Paris next time. We can visualize this process using decision boundaries, as shown in the video on the map. Over time, the network slowly shifts its boundaries (determined by the parameters) so that it correctly classifies input locations, and achieves a high accuracy. Want to learn more about ML? Accelerate your ML learning with our Weekly AI Newsletter—educational, easy to understand, mathematically explained, and completely free (link in bio 🔗). C: Deepia Join our AI community for more posts like this @aibutsimple 🤖 #deeplearning #neuralnetworks #mathematics #math #physics #computerscience #coding #science #education #machinelearning #datascience

In 2021, Adam Dhalla, a passionate high school student from Vancouver, Canada, recorded an impressive five‑hour lecture series on mathematics for neural networks and deep learning. His video, titled “The Complete Mathematics of Neural Networks and Deep Learning” covered everything from matrix calculus to cost-function gradients with full backpropagation. He accompanied the video with organized timestamps, a long syllabus and good production quality, shocking many users on YouTube as he was just 16 years old. Adam showed remarkable understanding of complex concepts in ML but also delivered them with an engaging teaching style and easy examples. Find his video on YouTube. Want to supercharge your career and ML learning? Read our Weekly AI Newsletter—educational, easy to understand, mathematically explained, and completely free (link in bio 🔗). C: Adam Dhalla Join our AI community for more posts like this @aibutsimple 🤖 #lecture #professor #mathematics #math #physics #computerscience #coding #science #education #machinelearning #deeplearning #datascience

Meet Suna, your new AI employee. Developed by Kortix AI, Suna is a generalist AI agent that analyzes files, browses the web, and writes up documents, slideshows and spreadsheets in one click. Suna is 100% open source and can be hosted locally, offering full transparency, security and customization. Save time and get tedious work done with Suna.
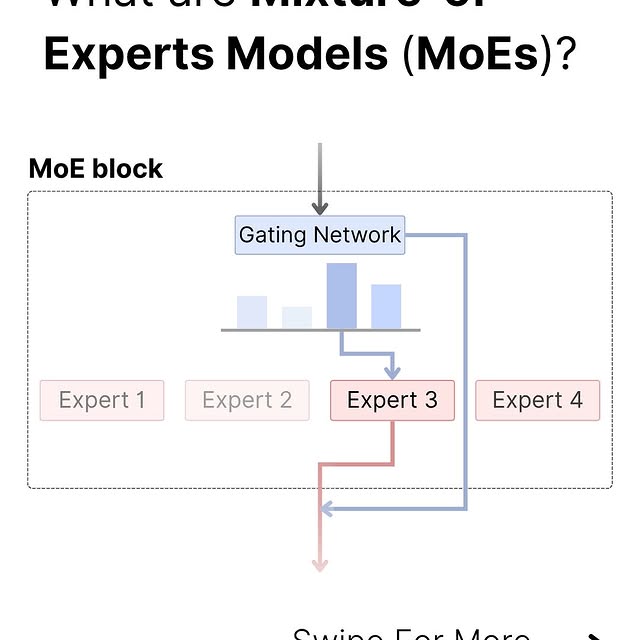
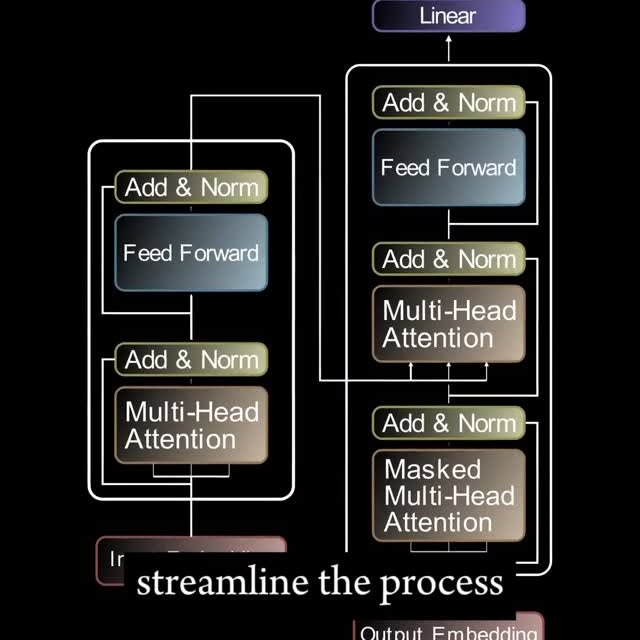
Mixture of Experts (MoE) models are a type of neural network architecture that scale efficiently without sacrificing performance. The idea behind them is similar to ensemble models: to assemble a group of candidates to produce the best output from all of the candidates. Instead of having one large, dense neural network trying to process all inputs, an MoE model uses multiple smaller, specialized neural networks called “experts.” Then, a gating network (or router) dynamically determines which expert, or combination of experts, is most suitable for processing a given input. By implementing both components, MoE models have scalable parameter counts while keeping the computational cost for each input relatively low. MoE allows models to be pre-trained with far less compute, meaning you can scale up a huge amount with the same compute budget as a dense model. Additionally, this also means that an MoE model should achieve the same performance as its dense counterpart much quicker during pre-training. Like this post? Accelerate your learning with our Weekly AI Newsletter; learn industry knowledge without the headache. It’s educational, easy to understand, mathematically explained, and completely free. #llm #deeplearning #coding #mathematics #math #computerscience #science #education #computerengineering #statistics #datascience 5.png
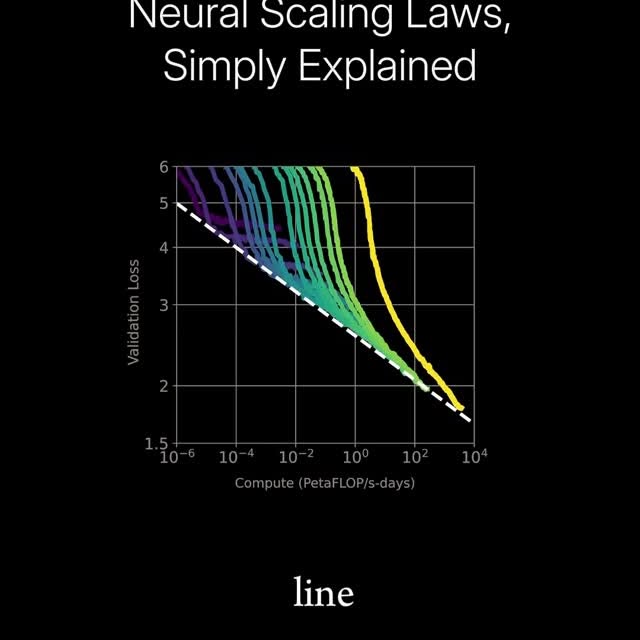
Neural scaling laws describe how a model’s performance improves (predictably) as we increase the amount of training data, the size of the model (in terms of parameters), or the total compute used (measured in FLOPs or floating point operations per second). The scaling laws are power laws, meaning that as we scale things up, the performance increases proportionally. For instance, as we increase the size of the model, we should expect better performance or lower loss proportional to how much the model size was increased. When we plot these relationships on a log-log plot (plots where both axes are logarithmic instead of linear) these power laws show up as straight lines, and the slope represents how quickly any factor scales. This kind of plotting helps researchers identify the most efficient way to improve performance, known as the compute-efficient frontier—where you get the most performance for a given amount of compute. Struggling with ML? Accelerate your ML learning with our Weekly AI Newsletter—educational, easy to understand, mathematically explained, and completely free (link in bio 🔗). C: Welch Labs Join our AI community for more posts like this @aibutsimple 🤖 #deeplearning #neuralnetworks #mathematics #math #physics #computerscience #coding #science #education #machinelearning #datascience
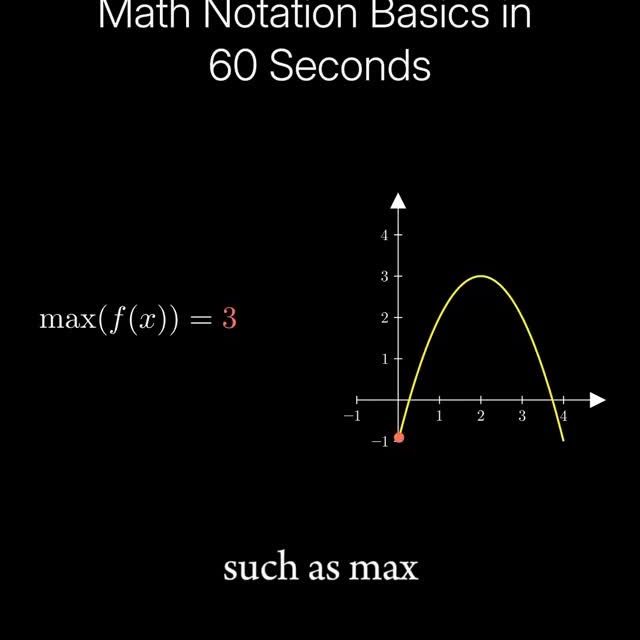
In machine learning, mathematical notation provides a precise way to represent complex concepts and operations. Basic arithmetic operations like addition, subtraction, multiplication, and division are commonly used in machine learning, along with more advanced tools such as summation, product, and integration. Greek letters such as alpha, beta, theta, and lambda often represent parameters, weights, or regularization terms. Uppercase and lowercase letters are often used and represent many different things. Vectors are usually written as bold lowercase letters, and matrices as bold uppercase letters, with individual elements identified using subscripts. Functions are typically some symbol with brackets and an input on the right, and they are used heavily in ML. For instance, activation functions are used in neural networks to introduce nonlinearity. Functions have many operators, and one such operator is the max function, which returns the maximum output value for any input value. Another such operator is the argmax function, which returns the input value that nets the largest output value. Want to supercharge your career and ML learning? Read our Weekly AI Newsletter—educational, easy to understand, mathematically explained, and completely free (link in bio 🔗). C: 3 minute data science Join our AI community for more posts like this @aibutsimple 🤖 #statistics #computerscience #coding #mathematics #math #physics #science #education #machinelearning #deeplearning #datascience #analyst #computerengineering
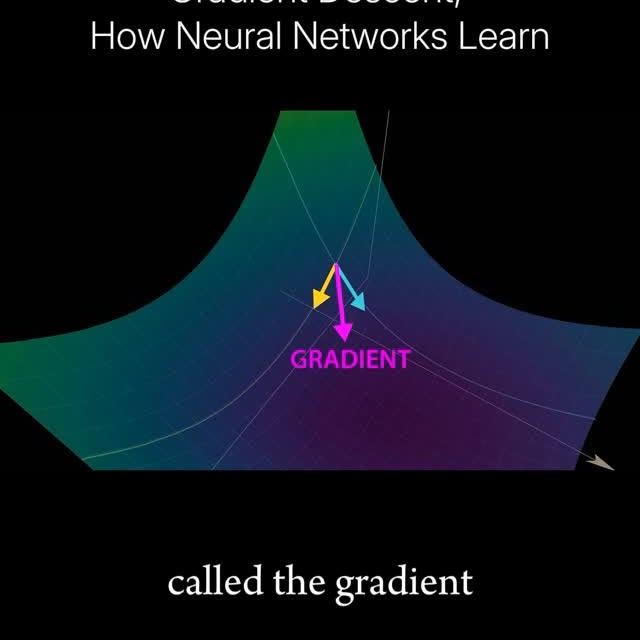
Gradient descent is a fundamental optimization algorithm used by most AI models to learn from data by minimizing a loss function, which measures how far the model’s predictions are from the true values. Conceptually, it treats the loss function as a landscape (we call this the loss landscape) with peaks and valleys representing high and low errors. At any point on this landscape, the gradient (vector of slopes) indicates the direction and steepness of the fastest increase in loss. Gradient descent uses the gradient to move in the opposite direction, downhill toward a valley, where the loss is minimized. With each step, the model adjusts its internal parameters (also known as the weights and biases) slightly to reduce the error, slowly improving its performance. This iterative process continues until the model reaches a point where further iterations don’t net much gain in performance. Or, in other words, the loss doesn’t change much. Essentially, this is how nearly all AI models “learn”: by following the gradient of the loss function to find parameter values that produce accurate predictions. Want to supercharge your career and ML learning? Read our Weekly AI Newsletter—educational, easy to understand, mathematically explained, and completely free (link in bio 🔗). C: Welch Labs Join our AI community for more posts like this @aibutsimple 🤖 #machinelearning #deeplearning #statistics #computerscience #coding #mathematics #math #physics #science #education #animation
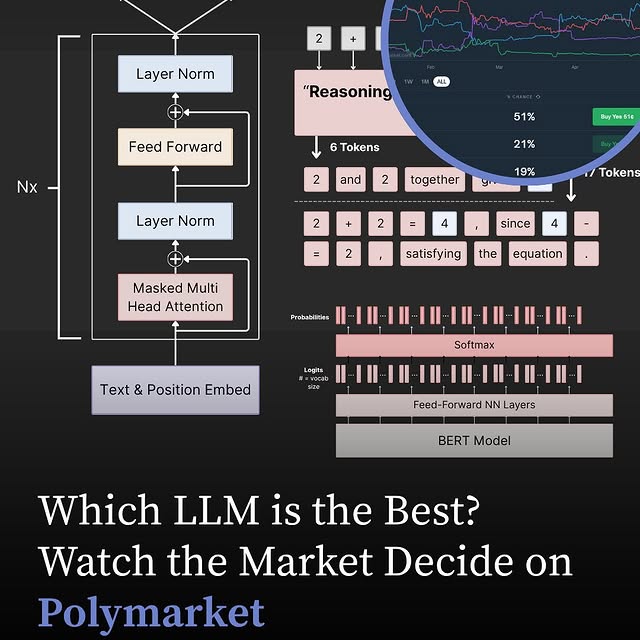
@polymarket is the world’s largest decentralized prediction platform, where users can place real-money bets on future events. From political outcomes to major tech shifts, the platform is now covering AI development. Al enthusiasts have a unique opportunity to bet on which company will build the best Al model. Whether it’s OpenAl, Google DeepMind, XAl, or Anthropic, you can back the company you think will dominate in performance, adoption, or innovation.

The chain rule is a basic idea from calculus that helps us understand how changes in one variable affect another through a chain of functions. In simple terms, if one thing affects a second thing, and that second thing affects a third, we can multiply the rates of change (derivatives) to find the overall effect. This is especially useful in artificial neural networks (ANNs), where each layer transforms its input and passes it to the next. During training, we use a process called backpropagation to adjust weights in the network. The chain rule lets us compute how a change in a weight deep in the network affects the final output by multiplying the gradients layer by layer—essentially chaining the rates of change. This is what allows deep learning models to learn complex patterns across many layers. Want to supercharge your career and ML learning? Read our Weekly AI Newsletter—educational, easy to understand, mathematically explained, and completely free (link in bio 🔗). C: Welch Labs Join our AI community for more posts like this @aibutsimple 🤖 #machinelearning #deeplearning #statistics #computerscience #coding #mathematics #math #physics #science #education #animation
Similar Influencers

Quantum Computing & Tech ⚛️

Prompted | Intelligenza Artificiale


Growth Forge AI

AI Strategies | Business Growth

Awakened Truths

CNET

Quantum | Agência de resultado

Physics Funny

the calculus guy

Rachel Barr | Neuroscientist

TECtalks

𝐂𝐡𝐢𝐩𝐮𝐥𝐚𝐫𝐢𝐭𝐲 ™ | 𝐓𝐞𝐜𝐡𝐧𝐨𝐥𝐨𝐠𝐲 | 𝐘𝐨𝐮𝐫 𝐄𝐝𝐠𝐞

Early Startup Days

Taylor Perkins (Cult Daddy)

Space Cameo

Nobel Prize

SCIENCE & TECHNOLOGY

Sinéad Bovell

Nathan Hodgson

AI Folks

Startup Archive

Space | universe | knowledge

Billy Carson

BBC News

David Marsh | Space for Earth

Lucio Arese

The Science Fact
NPR
